Error has occurred!
- KB479
- Mar 08, 2021 09:29 AM
How do I edit document text after OCR has been performed?
Symptoms
I cannot edit the text after I have performed OCR on a document.
Cause
V8 and up
With the latest releases of the PDF-XChange product line, we now offer an Enhanced OCR Plugin which is able to perform this process for you automatically. As of the Version 9 release, this feature is now included with PDF-XChange Editor Plus, or PDF-XChange PRO licenses.
V7 and prior
Please note that in version 7 and prior, the purpose of the OCR feature in PDF-XChange Editor was to make the text of scanned/image-based input documents searchable and selectable. When OCR is performed, PDF-XChange Editor identifies text-based content in input documents, then creates an invisible text layer over the original. This has the effect of converting image-based content into searchable/selectable text, but not Editable text.
Resolution
V8 an Up
In V8, if your license covers the new OCR plugin, this will be enabled by default and noted in the title of the OCR dialog, you will simply need to select the Editable Text and images, or the Fine page content options and then click OK:
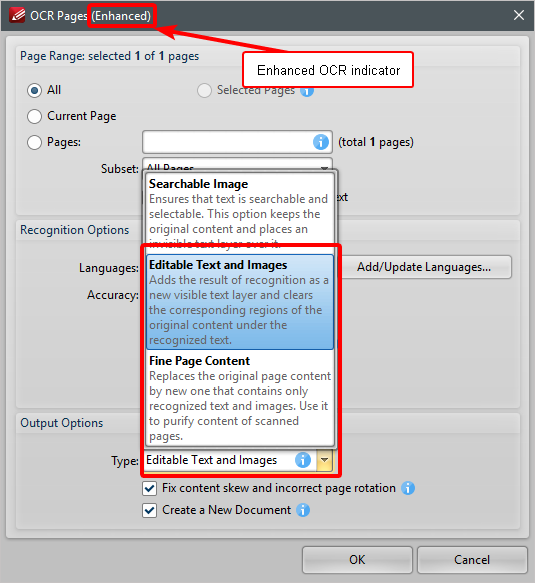
Once you have performed the OCR, you can begin Editing the text in the document as normal.
If the (enhanced) indicator is not present, you do not have the OCR plugin enabled. To enable this, you will need to ensure that:
1. Your license covers the OCR plugin If it does not, the option in step 2 will not appear.
2. The OCR options under preferences in the Editor and Tools are indeed set to "Enhanced"
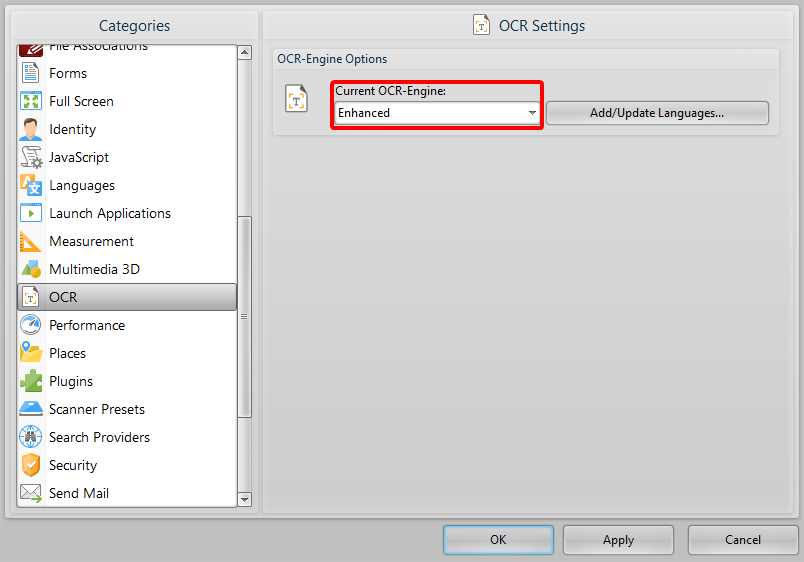
3. Restart the Editor so that this change can take effect.
More Like This
- KB#456: How Do I Customize toolbars in PDF-XChange Editor?
- KB#282: Why won't the "Send by E-mail" feature work in conjunction with Microsoft Outlook?
- KB#338: What are the MSI installation switch options for the PDF-XChange family of products?
- KB#447: How do I determine what version I should install/how can I retrieve my serial key?
- KB#195: What is the difference between Place Signature, Sign Document and Certify in PDF?